-
"뒤로 미루기"의 결과 : 2025 데이터 센터 화재잡다한 글 2025. 10. 11. 09:25728x90

2025년 9월 26일 밤, 대전 국가정보자원서비스(NIRS) 데이터센터에서 배터리 화재가 발생했다.
이 화재는 단순한 전력 장애를 넘어, 센터 내 전력 공급망 전체를 마비시켰다.
서버 랙과 UPS(무정전 전원장치) 일부가 손상되면서, 전력 라인이 자동 차단되고 냉각 시스템이 멈췄다.
결과적으로 수백 대의 서버가 순차적으로 셧다운되었고, 센터 전체가 오프라인 상태로 전환되었다.
그 여파로 정부24, 우정사업본부, 민원/청원 시스템 등 수백 개의 주요 서비스가 동시에 다운됐다.
119 긴급신고 위치추적 기능 등 일부 공공안전 연계 시스템까지 영향을 받으면서,
국가 단위의 온라인 행정 서비스가 사실상 ‘정지 상태’에 놓였다.
문제는 이 상황이 단순히 “서버가 불에 탔다”로 끝나지 않았다는 점이다.
정부는 백업 체계가 존재했다고 밝혔지만, 그 백업은 살아있는 서비스를 대신할 수 있는 구조가 아니었다.
즉, 백업 데이터는 있었지만, 즉시 서비스를 이어받을 다른 인프라가 없었다.
결국 복구는 ‘파일 복원’이 아니라 ‘시스템 재구축’ 단계부터 다시 시작되어야 했다.사고의 본질: 하드웨어가 아니라 아키텍처의 문제
이번 사태를 단순한 하드웨어 사고로 보면 본질을 놓친다.
근본 원인은 복원성(resilience) 과 가용성(availability) 이 부족한 아키텍처 설계에 있다.
현 정부 시스템의 많은 부분은 여전히 단일 데이터센터 중심 구조로 운영된다.
즉, 한 곳이 정지하면 다른 곳이 트래픽을 넘겨받지 못한다.이를 흔히 Single Point of Failure(SPOF) 라 부른다.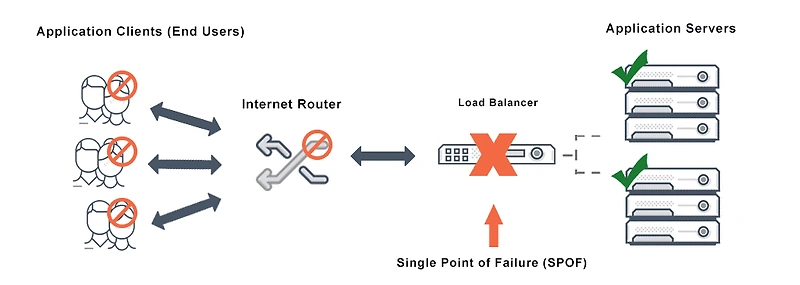
이번 화재는 바로 그 단일 실패 지점이 실제로 작동했을 때 어떤 결과가 나오는지를 보여준 사례다.백업이 있었는데 왜 막지 못했나?
많은 사람들은 “백업이 있었다면 복구하면 되는 것 아닌가?”라고 생각한다.
하지만 백업(backup) 과 무중단(High Availability) 은 완전히 다른 개념이다.
백업은 데이터를 보존하는 행위다. 즉, 일정 주기마다 데이터를 저장해두는 것으로, 복구 시점(snapshot) 이후의 변경분은 되살릴 수 없다.
반면 고가용성(HA)은 서비스를 유지하는 행위다.
장애가 발생하더라도 트래픽이 끊기지 않도록 설계된 구조를 말한다.
그런데 ...
G-드라이브의 백업은 “데이터 복사본” 형태였지만,
백업 저장소 자체가 동일한 데이터센터 내부에 위치해 있었다 (?)
즉, 화재가 난 그곳에 원본과 복제본이 함께 존재한 셈이다.
따라서 센터 전체가 셧다운되자, 백업 데이터 또한 접근 불가능해졌다.
결과적으로 “백업은 있었지만, 작동할 수 없었던” 구조였다.왜 Active-Active 구조가 필요한가
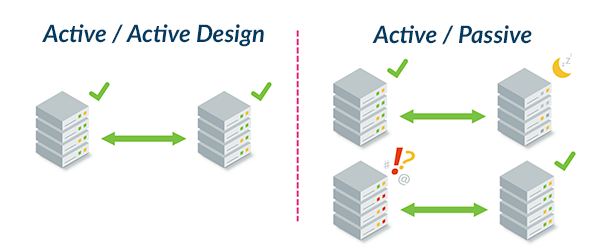
이 문제를 방지하려면 Active-Active 아키텍처가 필요하다.
이 방식은 단순한 “백업 센터”가 아니라,
두 개 이상의 데이터센터가 동시에 가동되며 동일한 데이터를 실시간으로 복제하는 구조다.
예를 들어 서울과 부산에 각각 센터가 있다고 가정하자.
서울 센터가 화재나 정전으로 마비되면, 부산 센터가 이미 같은 데이터를 실시간으로 가지고 있기 때문에
트래픽을 즉시 이어받아 서비스가 중단되지 않는다.
사용자는 장애 사실조차 모른 채 서비스를 이용할 수 있다.
이 구조의 핵심은 동기 복제(synchronous replication) 와 자동 트래픽 전환(failover) 이다.
모든 변경 사항은 두 센터에 동시에 기록되고, 한쪽이 실패하면 부하 분산 장치가 즉시 다른 쪽으로 요청을 우회시킨다.
이 때문에 복구시간(RTO)은 수초 이내, 데이터 손실(RPO)은 사실상 0에 가깝다.
반면 현재의 정부 시스템은 Active-Passive 수준도 아니었다.
Passive 센터조차 존재하지 않았기 때문이다.
결국 이번 사태는 “백업은 있었지만, 서비스는 하나뿐이었다”는 구조적 한계의 결과였다.구조적 단절: 이상적 아키텍처와 현실의 간극
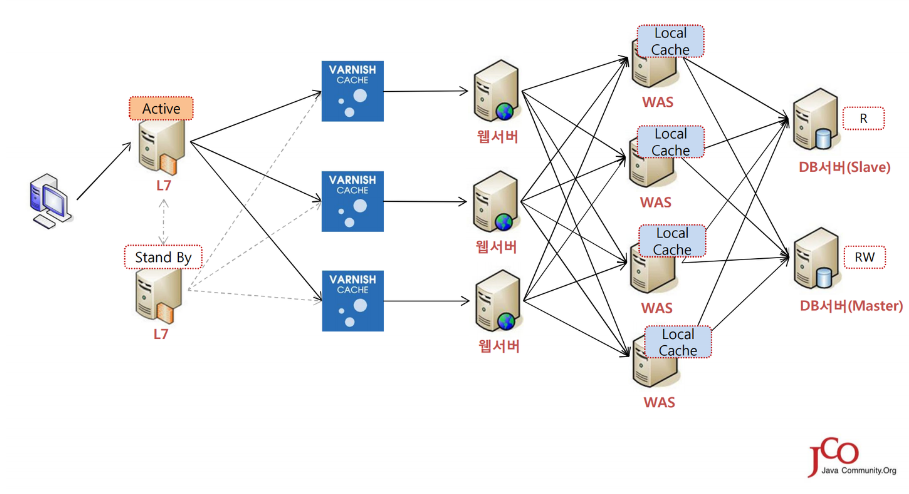
이미지 출처 - 제 14회 한국자바개발자 컨퍼런스 가이드집
비용문제가 있겠지만 이상적인 클라우드 기반 정부 시스템이라면, 여러 지역에 위치한 센터가 동시에 활성화되어 트래픽을 분산 처리한다.
장애가 발생하더라도 다른 리전(region)이 자동으로 역할을 이어받는다.
데이터는 실시간 복제를 통해 손실을 최소화하고, 전체 복구 목표(RTO/RPO)가 수초~분 단위로 정의되어 있다.
하지만 이번 사건 이전의 구조는 정반대였다.
모든 시스템이 단일 센터에 집중되어 있었고, 데이터 복제는 주기적 백업에 의존했다.
장애 발생 시 복구는 자동 전환이 아니라 운영자의 수동 복원 절차에 달려 있었다.
즉, 복구 시간은 길고, 데이터 손실은 크며, 가장 중요한 공공 서비스조차 즉각적인 대체 경로가 없었다.
이 구조에서는 백업이 아무리 많아도, 센터 자체가 불타면 그 백업은 사실상 존재하지 않는 것과 같다.카카오 화재사건과의 비교: 공통된 교훈

판교 데이터센터
2022년 카카오 판교 데이터센터 화재 사건 역시 본질은 같았다.
당시에도 전원 인프라 하나의 장애가 모든 서비스를 마비시켰다.
다만 카카오는 일부 서비스가 다른 리전으로 분산되어 있었기 때문에 일부 기능은 수시간 내 복구가 가능했다.
반면 G-드라이브는 리전 자체가 단일 구조였다.
단일 전원, 단일 저장소, 단일 네트워크 경로.
그 결과, 한 지점의 화재가 곧 정부 전체 시스템의 정지로 이어졌다.
둘 다 SPOF(단일 장애 지점)에 의존했지만, 민간은 최소한 일부 서비스의 연속성을 확보했고, 정부는 완전한 단절을 경험했다는 차이가 있다.우리가 얻어야 할 교훈
- 첫째, 복원성은 하드웨어가 아니라 구조에서 나온다.
서버를 더 두는 것이 아니라, 데이터센터 간의 관계를 설계해야 한다. - 둘째, 백업은 사후 대응일 뿐이다.
서비스 연속성은 실시간 복제와 자동 전환 구조에서 확보된다. - 셋째, 공공 인프라는 단일 센터 중심 구조로는 한계가 있다.
지리적으로 분리된 리전 간 동시 운영, 즉 Active-Active 구조로의 전환이 필요하다.
마무리

기술적 부채는 나중에 큰 대가를 치룬다. 이번 G-드라이브 화재는 단순한 사고가 아니라,
“지금의 공공 IT 구조가 어디서 멈춰 있었는가”를 명확히 보여준 사건이었다.
그동안 정부 시스템은 안정성 확보를 ‘다음 단계에서 할 일’,
즉, 당장의 운영과 예산 효율성 뒤로 미루는 경향이 있었다.
하지만 이번 사태는 바로 그 “뒤로 미루기”가 만든 결과다.
안정성은 선택이 아니라 기본이어야 한다.
이제 더 이상 “나중에 고치자”는 말은 통하지 않는다.
다음 사고가 발생하기 전에, 지금 구조를 바꾸는 것이야말로
진정한 디지털 정부로 가는 첫걸음이다.'잡다한 글' 카테고리의 다른 글
한 달 만의 이직, 그리고 내가 가고 싶은 길에 대해 + 마음가짐 (0) 2025.10.18 AI 시대, 결국 인간이 품질을 결정한다 : 휴먼 인더 루프가 만드는 새로운 일의 질서 (0) 2025.10.12 너도 개발자가 되라. 기획자 등 : 개발자의 소통법 (1) 2025.10.03 카카오톡 UI 개편이 남긴 교훈: 속도는 전략, 신뢰는 자산 (0) 2025.09.29 2025 상반기 회고록 : 온갖 (0) 2025.09.15 - 첫째, 복원성은 하드웨어가 아니라 구조에서 나온다.